
Running MaxDiff in the MX8 Research Platform
MaxDiff, short for Maximum Difference Scaling, is a survey technique to measure preferences or the relative importance of different attributes, products, or features. It involves presenting respondents with a series of choice sets, where they are asked to select the most and least preferred options from a list. By analyzing these choices, MaxDiff helps identify the most and least important factors in decision-making, making it a powerful tool for prioritizing options based on customer preferences.
You might use MaxDiff in scenarios where you need to understand what features or attributes are most valued by customers, such as in product development, marketing, or branding. For example, suppose you're developing a new product and want to know which features appeal most to potential buyers. In that case, MaxDiff can provide clear insights into what matters most to your target audience. It’s advantageous when you have many attributes to evaluate, as it forces respondents to make trade-offs, providing more discriminating data than traditional rating scales.
User Experience for MaxDiff
If we've got a study where we want to trade off between 14 different items, we only want to show some trade-offs to each user. We typically want to ensure that we mix up the trade-offs shown to each user and that each option is shown uniformly.
The MX8 platform will optimally create a set of trade-offs for each set of items and will display these to the user.
In the chatbot survey experience, this is shown as a series of questions:

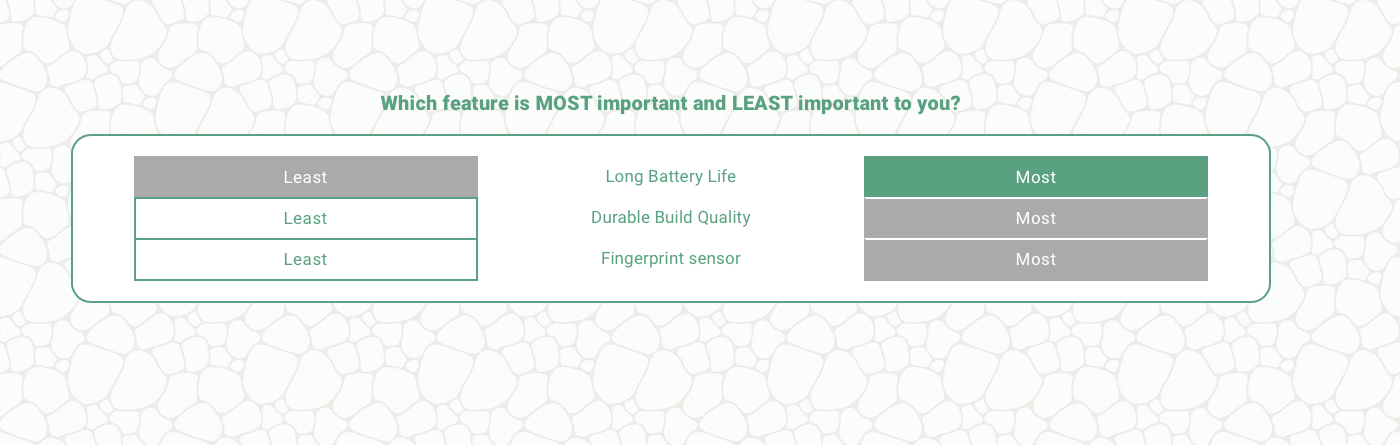
For the landscape survey experience, its shown using a grid, where the trade-offs are more explicit:
Reporting
We report MaxDiff questions using a simple cross-tabulation of each response.
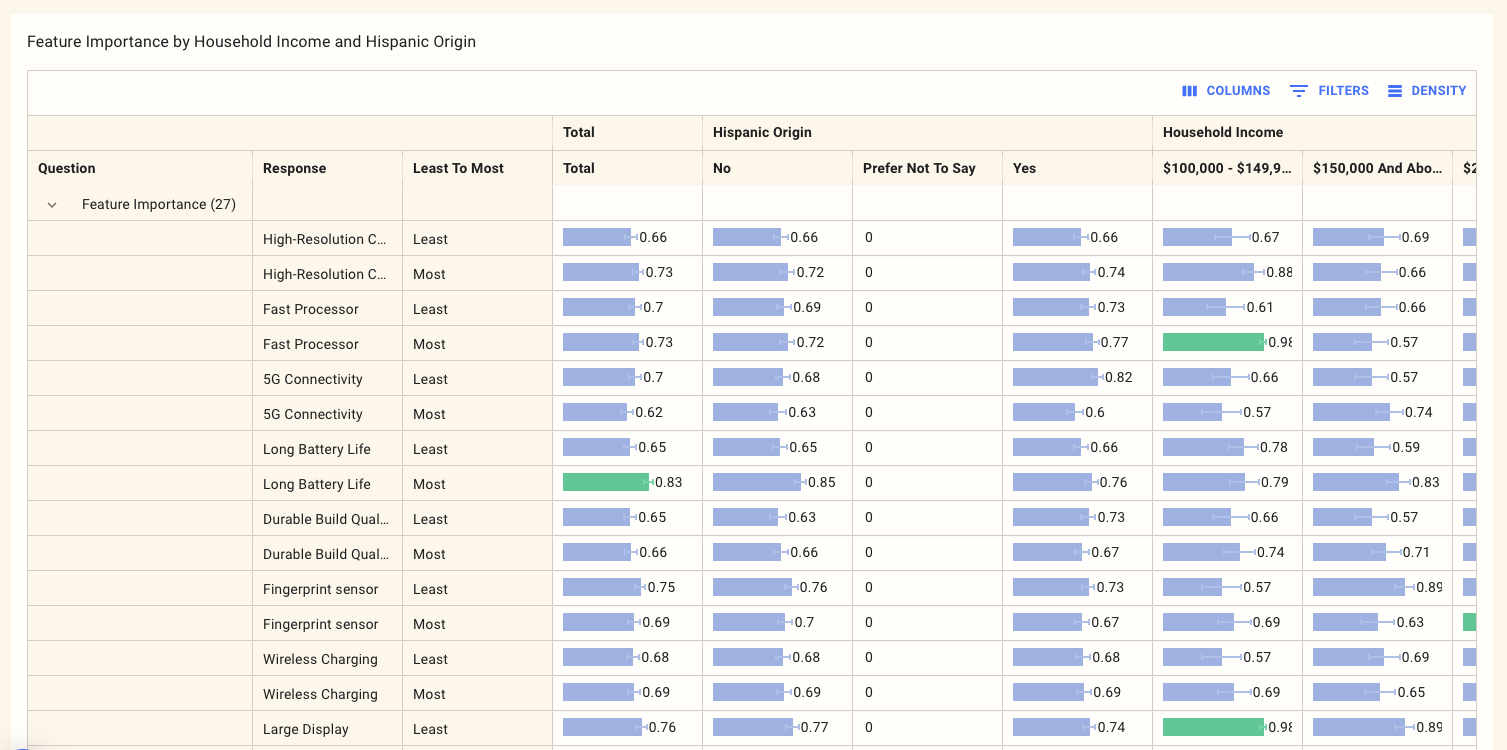
We have roadmap items to calculate part utility scores based on logistical regression and hierarchical bays models. If you'd like to sponsor the acceleration of these in the roadmap, please get in touch.
Why can't MX8 always calculate the sets?
When running max diff, it's imperative to ensure that:
a) All users see the same selection of sets.
b) Each option is asked the same number of times.
If you don't do a), you won't be able to slice your data across all demos because different groups will have been asked other questions. If you don't do b), then you're going to find your data is skewed towards one option simply because it's been offered as a choice more.
To fix this, we need to calculate a unique set of sets we can offer people that include the exact multiple of the number of items and repetitions. For example, if we've got 13 items we're testing and want two repetitions, we have to create sets from 26 items. For 14, it would be 28, etc...
Now, depending on the number of items we're dealing with, we are limited in the number of sets we can create and the set size. Going back to High School math, if we have 26 items, the prime factors of 26 are 13 and 2, which means we have two choices:
13 options per question and two questions
2 options per question and 13 questions
Neither of these is great from a consumer research perspective. 28, on the other hand, is much better, as the prime factors are 7 and 2, so we can have the following:
7 options per question and four questions
4 options per question and seven questions
Both are suitable, although I would prefer fewer questions and more options. If you want to test 13 options in max-diff, add another choice to improve the test.
And going back to your high school math, this is true any time you're running max diff on a prime number of items!
Example code
Here is an example for a simple Max Diff study:
from survey import Survey
s = Survey(**globals())
# Introduction
s.note(
"Welcome! Thank you for participating in our survey. We are conducting this study to understand the preferences and priorities of smartphone users. Your responses will help us improve future smartphone designs and features."
)
# Consent
consent = s.get_consent(
consent_text="Before we begin, we need your consent to participate in this survey. Your responses will be kept confidential and used only for research purposes."
)
# Screening Questions
# Age
age = s.multi_choice_question(
question="What is your age?",
options=["Under 18", "18-24", "25-34", "35-44", "45-54", "55-64", "65 and above"],
)
s.terminate_if(
age == "Under 18",
reason="Sorry, but this survey is only for people aged 18 and above.",
)
# Gender
s.multi_choice_question(
question="What is your gender?",
options=["Male", "Female", "Prefer not to say"],
)
# Ethnicity
s.multi_select_question(
question="What is your ethnicity? (Choose all that apply)",
options=[
"White",
"Black or African American",
"Asian",
"Other",
],
other_options=["Other (Please specify): __________", "Prefer not to say"],
)
# Hispanic Origin (For USA)
s.multi_choice_question(
question="Are you of Hispanic, Latino, or Spanish origin?",
options=["Yes", "No", "Prefer not to say"],
)
# Income
s.multi_choice_question(
question="What is your annual household income?",
options=[
"Less than $25,000",
"$25,000 - $49,999",
"$50,000 - $74,999",
"$75,000 - $99,999",
"$100,000 - $149,999",
"$150,000 and above",
"Prefer not to say",
],
)
# Education
s.multi_choice_question(
question="What is the highest level of education you have completed?",
options=[
"Less than high school",
"High school diploma or equivalent",
"Some college, no degree",
"Associate degree",
"Bachelor's degree",
"Graduate degree",
"Prefer not to say",
],
)
# Smartphone Ownership
smartphone_ownership = s.multi_choice_question(
question="Do you own a smartphone?", options=["Yes", "No"]
)
s.terminate_if(
smartphone_ownership == "No",
reason="Sorry, but this survey is only for people who own a smartphone.",
)
# Loop through each MaxDiff set and ask the question
s.max_diff_question(
question="Which feature is MOST important and LEAST important to you?",
items=[
"High-Resolution Camera",
"Long Battery Life",
"Fast Processor",
"Water Resistance",
"Wireless Charging",
"Large Display",
"Face Recognition",
"Ample Storage Space",
"5G Connectivity",
"Affordable Price",
"Durable Build Quality",
"Wide Range of Apps",
"Fingerprint sensor",
"Dual SIM capability",
],
labels=["Least", "Most"],
)
# Conclusion
s.note(
"Thank you for participating in our survey. Your responses are valuable to us and will help shape the future of smartphone technology. Have a great day!"
)
# Finalize the survey
s.complete()